ICCV 2019 画像認識技術の最新動向レポート
2019年11月15日(金)
ICCV2019とは
ICCVとは「International Conference of Computer Vision」の略で、Computer Vision分野では最も権威のある国際会議(トップカンファレンス)の一つです。2年に一回開催されています。
Computer Visionとは、コンピュータに人間の視覚を与えることを目指す技術領域です。画像・映像の認識技術が含まれ、最近では画像・映像の自動生成技術も登場してきています。
今年は韓国のソウルで開催され、江南と呼ばれるエリアにあるCOEX(コエックス)というコンベンションセンターが会場でした。開催期間は2019年10月27日〜11月2日の7日間です。



技術トレンド
近年はDeep Learningという機械学習手法による飛躍的な精度向上によって、ほとんどの研究はDeep Learningが当然のように使われています。
ICCV2019でもDeep Learningをベースにした研究発表が大半を占めていました。
数年前までのコンピュータビジョン分野では、画像・映像から物体を認識・検出する話(物体認識、物体検出)が中心的なテーマでしたが、最近ではもう一歩進んだ研究がトレンドになっているように感じます。
ホットなテーマをいくつかピックアップしてご紹介します。
GAN
コンピュータビジョン分野で今一番ホットな話題といっても過言ではないGAN!
GANとはGenerative Adversarial Networksの略で、教師画像を使って学習させたDeep learningモデルから、逆に新しく画像を生成する技術です。
次の画像をご覧いただければ、GANのインパクトがわかると思います。
この動画では、3枚の顔画像を合成することで、実在しない人物の顔画像(フェイク画像)を生成しています。
今回のICCV2019でもGANに関連する発表が盛りだくさんでした。
Best Paper Awardに選ばれたのもSinGANという新たなGANモデルに関する論文です。SinGANの論文ではいくつかの画像生成の応用例を示しています。

左から、簡単なペイント画像からリアルな風景画像を生成する例、建物の大きさを変えた画像を生成する例、2つの風景画像を調和させる例、低解像度の画像から高解像度の画像を生成する例、アニメーションを生成する例を示しています。
他には、顔写真を若くしたり老けさせたりする応用や、アナウンサーが話しているような映像を自動生成する応用など、GANに関連する様々な研究発表がされていました。
GANはまだ発展途上で、学習が不安定で収束しなかったり、局所解に陥ったりする(mode collapse)などの技術課題はありますが、今後研究が進むにつれて産業分野への応用も増えてくると感じています。
Multimodal learning(マルチモーダル学習)
教師データとして画像だけでなく、音声やテキストといった異なる属性の情報を使って学習させることをマルチモーダル学習と言います。人間は五感を使って物事を認識することと同様に、機械学習でも様々な種類の情報を統合して学習させようという考え方です。
例えば、音声と画像の情報から感情を推定するということができるようになります。
近年では、Deep learningによりマルチモーダル学習の研究は更に進んできています。
今回のICCV2019でも、動画から内容説明する文章を生成する研究(Video Captioning)などいくつか目にしました。

Video Captioningでは、例えば料理のクリップ映像から「バジルを刻んでボウルに入れている」などといったシーン説明の文章を自動生成することができます。

また、料理のクリップ映像から未来に起こるだろうとするクリップ動画を検索するといった応用もできるということです。例えば、ピザを焼く前の映像にもとづいてピザを焼き終わった映像を検索することができます。
いままで画像・音声・テキストはそれぞれ独立した領域として研究が行われていましたが、クロスモーダル学習によって横断的に利用する機会が増えてきました。
画像認識シンポジウムのMIRU2018でも音声認識や自然言語処理の研究動向を共有する趣旨のチュートリアルがありましたが、今後モーダルの境界線は徐々に薄くなっていく流れなのだと感じます。
Re-identification
カメラに写った対象物(人物や車両など)を識別・同定させることをIdentificationと言います。Identificationによって映像中にある特定の対象物を正確にトラッキング(追尾)することができます。
Re-identificationとは、一度Identificationされた対象物が複数の監視カメラをまたがって撮影された場合でも、再度Identificationを行うことによって対象物のトラッキング(追尾)を行うための技術です。
たとえば街中に設置されている複数の監視カメラを使って、特定人物をトラッキングするようなことができるようになります。

(Omni-Scale Feature Learning for Person Re-Identification)
複数カメラ間をまたぐトラッキングでは、同一対象物であっても対象物の向きや大きさ等によって映り方が大きく変わりますので、対象物固有の情報をいかに安定的に抽出できるかが重要となります。
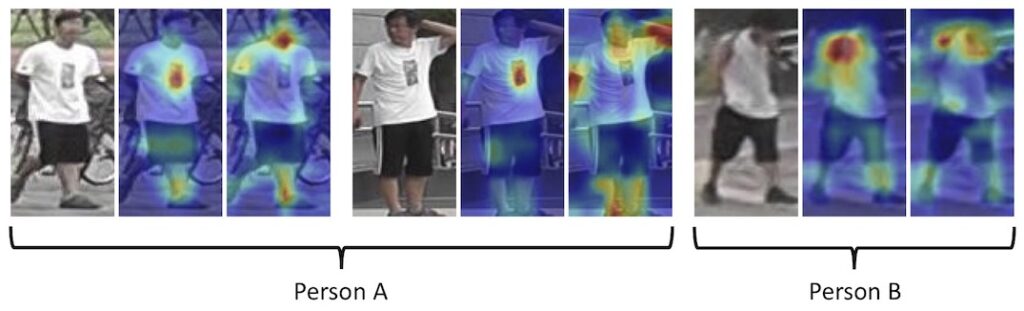
(Omni-Scale Feature Learning for Person Re-Identification)
ICCV2019ではRe-identificationに関する発表も多くあり、ニューラルネットによって人物を特徴づける領域を推定する方法などが提案されていました。
この分野は圧倒的に中国が進んでいるようです。
Human pose estimation(人物姿勢推定)
Human pose estimationは、人が姿勢でいるかを推定する技術です。
下図の例では、人間の関節を特定して、グラフ化することで姿勢を表現しています。

(Single-Stage Multi-Person Pose Machines)
画像上では服や他の障害物に隠れて見えない部分も多く、関節の位置を特定することが難しく課題となっています。
この技術領域はかなり昔から研究されている分野ですが、近年ではDeep learningを使って姿勢推定の精度が大幅に向上しており、ICCV2019でもHuman pose estimationに関する研究発表がいくつかありました。
応用研究としては、体操競技の自動採点を目的として、理想的な動きにどれだけ近いかを自動スコア化させる等の発表がありました。
ビジネス分野での活用
GANについては現時点でエンターテインメント分野で利用されつつあります。
例えば顔写真を加工して表示させるようなスマホアプリでは既に製品化されているようです。
GANはまだ研究途上の技術ですが、今後は下記のような応用に展開できるようになるのではと思います。
・画像素材やイラストの自動生成
・商品デザインの自動化
・データ拡張(Data Augumentation)への応用
学習モデルを構築するためには大量の教師画像が必要ですが、実現場においては画像を充分に集めることが難しい場合が少なくありません。例えば、製造ラインの検品を目的とした物体認識モデルを構築する場合、不合格ラベルの教師データも必要になりますが、一般的な工場では不合格品はそうそう発生するものではありませんので充分な枚数の収集が困難だったりします。
GANを用いると、本物の画像に近い偽物の画像を生成できますので、不合格品のフェイク画像を大量に自動生成することができます。これによって教師データのかさ増しができるようになります。
GANによって機械学習の適用範囲が広がっていくのではないかと思います。
Re-identificationは中国を中心に既に実用化が進んでいて、セキュリティ産業に展開が広がっていくのではないかと思います。また、動線分析といったマーケティング分野にも展開できるだろうと感じています。
Human pose estimationもスポーツ科学やエンターテインメントの分野では実用化が進んでいます。
ただし人物をカメラでセンシングするという点で、日本においてはプライバシー保護を配慮した運用方法が求められます。
画像を活用したソリューションをご検討中の方へ
当社では画像を活用したAIソリューションのご提案と開発を行っております。
お客様のビジネス課題に合わせたソリューションのご提案をさせていただきますので、ぜひお気軽にご相談ください。
横浜にある小さなベンチャー企業ですが、実証実験(PoC)を通した技術開発やプロトタイプ提供など小回りの聞く開発を得意としております。
リモートでのお打合せにも対応可能ですので、遠方のお客様もお気軽にお問い合わせください。